The Web
The Web, or more pompously the World Wide Web, from which comes the famous acronym www, is the global web that we use every day. The Web has been so successful in recent years and has made the Internet accessible to so many people that it is often confused with the Internet itself. In reality, there is a certain difference between the Internet and the Web: the Internet is a network of networks, or rather, it is a set of networks so large that it covers the entire world, and is therefore the infrastructure on which the Web is based. The Web, on the other hand, is This is just one of the many applications that can run on the Internet.
The Web is based on the so-called client/server model, which we will now analyze.
The Client/Server Model
Most applications supported by any network are based on the client/server model. Take, for example, an application designed to access remote files. It is characterized by a pair of processes—in computing, a process is a running program. For simplicity, we will assume that the two processes are located on two separate machines, one requesting read or write access to the remote file, and the other honoring that request. The process requesting access to the file is called the client, a term which usually also refers to the PC on which that process runs. The process providing access to the file is called the server, as is the case with the client. such as the machine on which that process is executed.
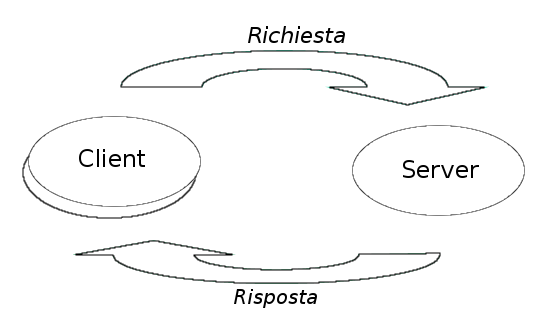
Interactions between clients and servers are always of the request/response type: the client sends a request message to the server, which performs the requested service and sends the client a response message, which varies based on the requested service.
The Web: HTTP and URLs
The Web can be thought of as a set of clients and servers interacting with each other, using the HTTP protocol as a common language. The Web is commonly viewed through a client program with a graphical interface, called a browser. Well-known browsers include Google Chrome, Firefox, or Safari.
On the web, each object (such as a music file or an image) is uniquely identified by a URL (Uniform Resource Locator), a sequence of characters that provides information on how to locate that object. The simplest example of a URL is the following:
http://www.google.it/index.html
This URL is made up of three parts:
httpis the type of protocol used to exchange information;www.google.itis the domain name, which identifies the website address;index.htmlis the URL. the name of the requested file (in this case, an HTML page).
When this particular URL is typed into the browser, what happens is that the browser opens a connection to the web server running on a machine whose IP address matches the domain name www.google.it. This connection is typically a TCP connection, through which the browser immediately receives and displays the file named index.html.
Now, to be precise, URLs can be even more complicated than the example given. For example, they could look generically like this:
protocol://host[:port]/path[?querystring][#fragment]
In this formulation, optional parameters are highlighted by placing them in square brackets. The fields have the following meaning:
protocolis the type of protocol used to exchange information (http, https, etc.);hostis the server we want to contact, specified as an IP address or domain name;portis the port number on which the network service is listening;pathis the pathname of the resource being requested by the client;querystringis the string with which the client sends parameters to the server;fragmentis mainly used in web pages to indicate a position within the page.
